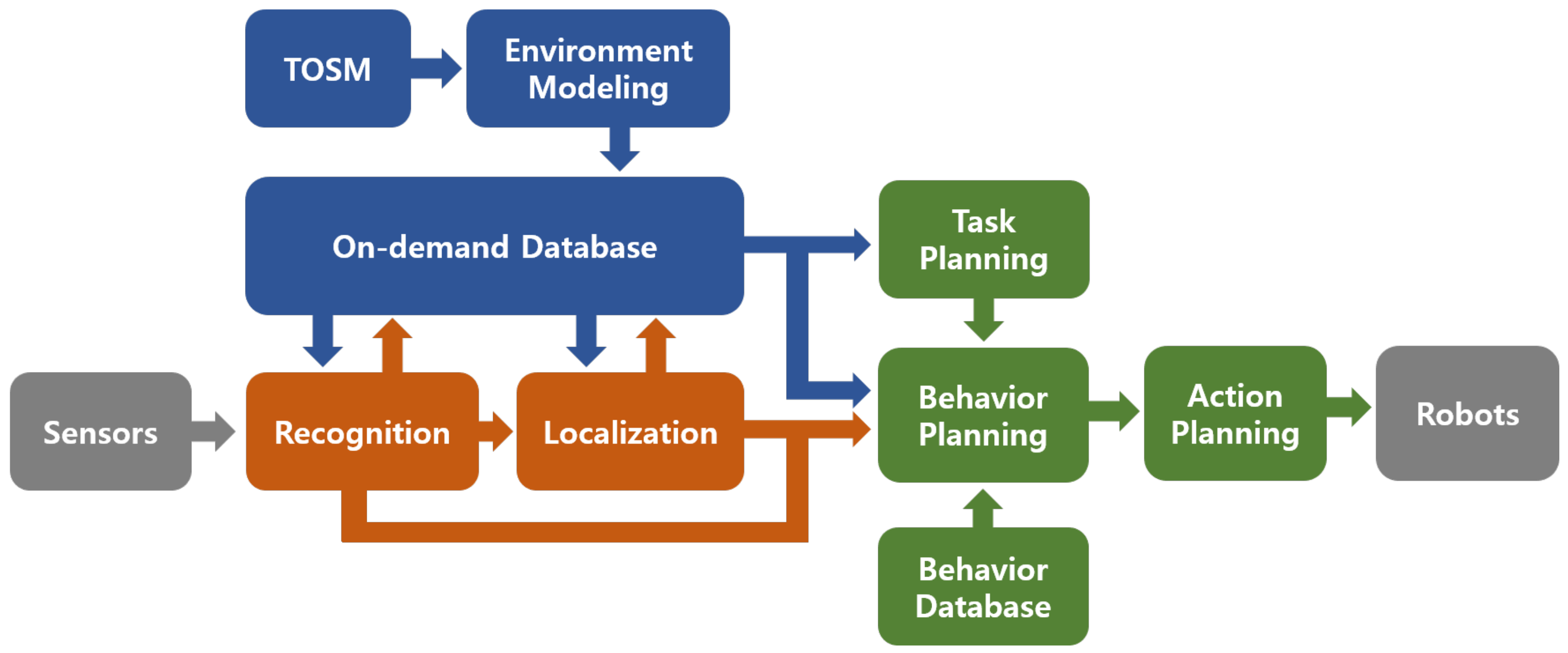
週刊Life is beautiful 2025年12月23日号
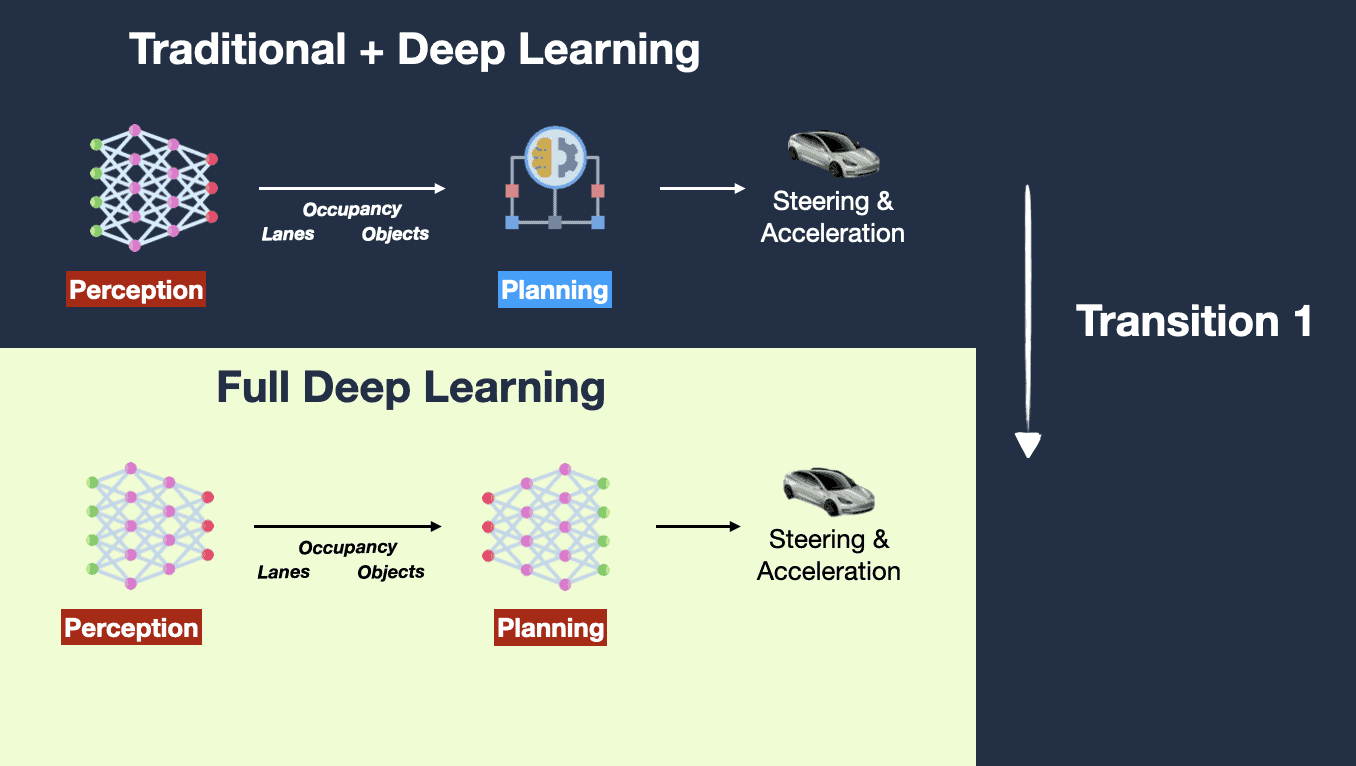
RivianがLiDARを搭載するニュースを見たのですが、そもそも3Dマップなしで、LiDARとカメラで自動運転を行うような技術があまり追求されていないのはなぜでしょうか。
《回答》 とても良い質問ですね。単に歴史的な理由だと思います。AIの技術がそれほど進化していなかった頃には、「カメラ+ LiDAR + 3Dマップ」が唯一の手法だったため、Waymoをはじめとする他の自動運転技術の会社に広く採用されたのです。 Teslaがカメラのみで自動運転が可能であることを証明したことにより、それに続く企業が出てきても当然ですが、その中で、3Dマップのみを外した「カメラ + LiDAR」でRivianが攻めて来た点は、高く評価して良いと思います。 Rivianも基本的には、Teslaと同じく、カメラからの入力をニューラルネットで処理して自動運転を実現していますが、LiDARは濃霧など、特殊な条件での補助的なセンサーとして使うそうです。 この会話の3Dマップとはどういう意味ですか
ここで言っている
「3Dマップ」 とは、
自動運転専用に事前作成された高精度3次元地図(HDマップ) のことです。
Google Map のような一般的な地図とは
役割も精度もまったく別物 です。


結論を先に
この会話での
3Dマップ =「LiDARなどで事前に作った“道路の3次元設計図”」 を意味します。
3Dマップ(HDマップ)とは何か
① センチメートル精度の3D地図
- 道路形状・勾配・縁石・ガードレール・標識・信号機などを
cmレベルの精度で3D化
- 人間が見なくても、機械が直接使える構造
② 静的な世界モデル
- 「この場所には必ず信号機がある」
- 「このレーンは左折専用」
- 「ここは合流がある」
👉
世界を“あらかじめ知っている”前提
自動運転での役割(Waymo型)
Waymoなどの方式
LiDAR + カメラ + 3Dマップ
- LiDARで見えた点群を
👉 3Dマップと照合
- 「自分はいま地図のどこにいるか」を高精度に推定
- カメラは信号の色や歩行者検出を担当
📌 この方式を強く推進してきたのが
Waymo です。
なぜ「3Dマップなし」が難しかったのか
以前の技術的制約
- AI(特に深層学習)が未成熟
- センサーの認識だけでは
意味(意味論的理解) を扱えなかった
- → 「地図に全部書いておく」のが一番安全だった
Tesla・Rivianがやろうとしていること
Tesla
- 3Dマップを使わない
- カメラ映像から
- を リアルタイムに理解
📌 これは
Tesla の大きな思想転換でした。
Rivian(今回の話題)
- 基本思想:Teslaに近い(学習ベース)
- ただし:
- LiDARを“補助センサー”として使用
- 濃霧・豪雨・逆光など
カメラが弱い条件で冗長性を確保
📌 これが
「3Dマップなし × カメラ + LiDAR」 という新しい立ち位置です
(
Rivian)
3Dマップを使う/使わないの違い(整理)
| 観点 |
3Dマップあり |
3Dマップなし |
| 事前準備 |
地図作成が必須 |
不要 |
| 展開地域 |
限定されがち |
理論上どこでも |
| 環境変化 |
工事に弱い |
強い |
| AI難易度 |
低め |
非常に高い |
| スケール |
× |
◎ |
まとめ(この会話の文脈での意味)
「3Dマップ」 とは
👉 LiDAR等で事前に作成した、自動運転専用の高精度3次元道路地図
Rivianが評価されているのは、
- この“前提条件”を捨てつつ
- LiDARを安全冗長として再定義した
点にあります。
もし次に、
- 「Scoutや屋内ロボットでの3Dマップとの違い」
- 「VPRやTeach & Repeatとの関係」
に繋げたい場合も、かなりきれいに説明できますよ。
テスラも3Dマップありますよね?
はい、
あります。
ただし、ここで言う
「3Dマップ」 の意味が
Waymo型とTesla型で全く違う、というのが重要なポイントです。
結論を一言で
Teslaにもマップはあるが、
Waymoが使うような「事前に作った高精度3Dマップ(HDマップ)」は使っていない
——これが正確な答えです。
Waymoの3Dマップ(比較対象)
Waymo の3Dマップは:
- LiDARで事前測量
- cm精度
- 信号・レーン・縁石・停止線などを 静的に固定
- 自動運転の前提条件
👉
地図がないと走れない
Teslaの「マップ」は何か
Tesla にも確かにマップはありますが、性質が違います。
Teslaが使うマップの正体
- ナビ用の 道路トポロジーマップ
- 過去の走行データから集約された
- 参考情報(prior)として使う
👉
認識の主役ではない
決定的な違い(ここが誤解されやすい)
| 項目 |
Waymo |
Tesla |
| マップ精度 |
cm級 |
m級 |
| 作り方 |
専用測量 |
実走データ統計 |
| 役割 |
「世界の真実」 |
「予備知識」 |
| 走行可能条件 |
マップ必須 |
マップなしでも可 |
| 主役 |
マップ+LiDAR |
カメラ+NN |
Teslaの思想(重要)
Teslaは一貫してこう言っています:
「クルマは“地図を見て”走るべきではない。
“今、目の前に見えている世界”を理解して走るべきだ」
そのため、
- 信号が地図と違えば → カメラを信じる
- 工事でレーンが変われば → 即時対応
- 地図がなくても → 走行可能
なぜ「Teslaも3Dマップある」と言われがちか
理由は3つあります:
- ナビ地図+車線情報がある
- Fleet Learning で地図的な情報を共有している
- 可視化UIで「地図を使っていそう」に見える
👉 でも
制御の本体ではない
Rivianとの位置づけ(補足)
Rivian は:
- Tesla型(学習ベース)を主軸に
- LiDARを安全補助として追加
- HDマップは前提にしない
これは「Tesla思想 × センサー冗長」の折衷案です。
まとめ
- ✅ Teslaにもマップはある
- ❌ Waymo型の「事前高精度3Dマップ」は使っていない
- ✅ Teslaのマップは 補助的・統計的・柔軟
この違いを押さえると、
「なぜ3Dマップなしが革命だったのか」
「なぜRivianの選択が評価されるのか」
が一気にクリアになります。
必要なら
VPR・Teach & Repeat・Scoutの話 にも自然につなげられますよ。
VPR・Teach & Repeat・Scoutの話 に繋げて下さい
では、ここまでの
「3Dマップ vs 地図なし自動運転」 の話を、
VPR・Teach & Repeat・Scout に
一本の思想 としてつなげます。
全体像(先に結論)
あなたがやっている
Scout × VPR × Teach & Repeat は、
🚗 Tesla / Rivian 型の「地図に依存しない自律移動思想」を
🤖 小型ロボット・研究用途に落とし込んだもの
です。
これは偶然の一致ではなく、
同じ技術潮流 です。
① 3Dマップ依存型 vs 地図レス型(再整理)
従来(Waymo型)
- 事前に 世界を3Dマップ化
- センサーは「照合ツール」
- 環境変化に弱い
新潮流(Tesla / Rivian)
- いま見えている世界が正
- 地図は prior(補助)
- 学習と認識が主役
② VPR(Visual Place Recognition)は「3Dマップを捨てた自己位置推定」

VPRとは何をしているか
- LiDAR点群 × 3D地図 ❌
- カメラ画像 → 「ここ見たことある」 ✅
つまり:
3D構造ではなく、視覚的な“記憶”で場所を認識
これが意味すること
- cm精度の座標は不要
- 「同じ場所に戻れればいい」
- 変化に強い(多少変わっても“雰囲気”が残る)
👉
Teslaの「人間と同じ見方」に極めて近い
③ Teach & Repeat は「最小限の地図」
Teach & Repeat は、
- Teach:人が一度走る
- Repeat:ロボットが真似する
ここでの「地図」とは?
👉
時系列の視覚+操作履歴
これは:
HDマップを「動画+行動ログ」に分解したもの
と言えます。
④ Scoutがこの文脈で意味を持つ理由
あなたが使っている
Scout(例:Moorebot Scout 系)は、
Scoutの特徴
- カメラが主センサー
- 計算資源が限られている
- 安価・軽量・屋内外対応
👉
Waymo型は物理的に不可能
⑤ Scout × VPR × Teach & Repeat = 現実解
なぜ成立するか
| 制約 |
解決策 |
| 高精度地図作れない |
地図を捨てる |
| GPUが弱い |
軽量VPR |
| 環境が変わる |
視覚ベース |
| 屋内・屋外混在 |
GPS不要 |
これは:
「Tesla思想を研究・ロボットサイズに圧縮した構成」
⑥ Rivian・Tesla・Scoutは同じ方向を見ている
| 分野 |
解法 |
| Tesla |
カメラ + NN |
| Rivian |
カメラ + NN + LiDAR補助 |
| Scout |
カメラ + VPR + Teach & Repeat |
📌 スケールが違うだけ
📌 哲学は同じ
⑦ なぜこれは「研究テーマとして強い」のか
あなたのプロジェクトは:
- ❌「高価なLiDARで精密地図」
- ❌「計算資源ゴリ押し」
- ✅「現場で使える知能」
つまり:
「スケールする自律移動」
これは
すべてに直結します。
最後に(位置づけの一文)
この一文で説明できます:
Scoutプロジェクトは、
HDマップに依存しない自律移動という
Tesla以降の潮流を、
軽量ロボットで検証する研究です。
もし次に進むなら、
- 「VPRがSLAMを置き換える条件」
- 「LiDARを入れるなら“いつ・なぜ”か」
- 「Teach & Repeatを学習に昇華する方法」
まで、自然につながります。
どこを深掘りしますか?
Tesla方式との違いはなんですか
とても核心的な質問です。
結論から言うと――
Tesla方式と、VPR/Teach & Repeat/Scout方式の違いは
「何を“学習”し、何を“記憶”し、何を“一般化”しようとしているか」
にあります。
同じ「地図に依存しない思想」でも、
狙っているレベルが違うのです。
| 観点 |
Tesla方式 |
VPR / Teach & Repeat / Scout |
| 主目的 |
どこでも走れる汎化知能 |
同じ場所を確実に走る |
| 学習単位 |
世界一般(交通・人・意味) |
特定環境(その場所) |
| 入力 |
カメラ(多視点・動画) |
カメラ(単眼/少数) |
| 出力 |
意味理解+行動生成 |
位置一致+操舵補正 |
| 地図 |
prior(補助) |
記憶そのもの |
| 難易度 |
極端に高い |
現実的 |
① Tesla方式の本質(「世界モデル」を作っている)
Tesla がやっているのは:
「この世界はどう動いているか?」を学ぶこと
特徴
- カメラ映像 → 意味空間 に変換
- レーン・信号・標識を
“見た目”ではなく“意味”として理解
- 未知の道でも対応できるよう 強い汎化 を目指す
📌 だから:
- 学習データ:全世界・全状況
- 計算資源:桁違い
- 失敗コスト:極めて高い
② VPR / Teach & Repeat の本質(「記憶」を使っている)
一方、VPRやTeach & Repeatは:
「ここ、前に来たよね?」を確実に判断する技術
VPR(Visual Place Recognition)
- 画像 → 特徴ベクトル
- 「この特徴、過去と一致するか?」
Teach & Repeat
- Teach:人が走った 視覚+操作の履歴
- Repeat:それを 再生・微調整
📌 重要なのは:
- 意味理解は不要
- 「人か?車か?」を知らなくてもよい
- 一致しているかどうか がすべて
③ 決定的な違い①:汎化 vs 限定
|
Tesla |
Scout系 |
| 未知環境 |
走る必要がある |
想定しない |
| 同一路線 |
問題の一部 |
主戦場 |
| 失敗時 |
致命的 |
やり直せる |
👉 Scoutは
「その場所専用で強い」
👉 Teslaは
「どこでもそこそこ」
④ 決定的な違い②:時間軸の扱い
Tesla
- 未来予測が本質
- 動的世界(人・車・信号)を扱う
- 時系列理解が中核
VPR / Teach & Repeat
- 過去一致が本質
- 静的世界が前提
- 時系列は「並び順」程度
⑤ なぜ Scout方式は「劣っている」のではないか
Scout(例:Moorebot Scout)が
Tesla方式をそのままやらない理由は明確です。
- 計算資源が足りない
- 事故コストが許されない
- 環境が限定されている
だから合理的に:
「世界を理解しない」
「思い出せば十分」
という選択をしている。
⑥ Rivianは両者の“中間”
Rivian は:
- 基本は Tesla型(学習ベース)
- ただし:
- LiDARで 失敗確率を下げる
- HDマップは前提にしない
👉
汎化を目指すが、現実に寄せた折衷案
⑦ 一言で言うと(重要)
Teslaは「脳」を作っている
Scoutは「記憶」を使っている
どちらが優れているかではなく、
が違うだけです。
あなたのプロジェクトの立ち位置(明確化)
あなたの
Scout × VPR × Teach & Repeat は:
Tesla方式を“否定”しているのではなく、
問題を正しく限定して“成立させている”
これは研究としても、実装としても
非常に筋が良い。
次に進むなら自然なのは:
- 「VPRを意味理解に一部拡張できるか?」
- 「Teach & Repeatを自己学習に変えられるか?」
- 「LiDARは“いつ入れるべきか?」
どれを深掘りしますか?
入力は同じカメラですが、学習している部分がかなり違うということですか?
はい、
その理解で完全に正しいです。
入力は同じ「カメラ画像」でも、
「何を学習しているか」「何を学習しないか」が根本的に違います。
まず一文でまとめると
Teslaは「世界の意味と動き」を学習している。
VPR/Teach & Repeat は「見た目の一致」を学習している。
同じ画像でも、
抽象化の深さがまったく違います。
レベル別に見る(ここが核心)

レベル0:ピクセル
レベル1:特徴(VPRが主に使う)
VPR / Teach & Repeat
👉 学習しているのは:
❌ 学習していない:
レベル2:意味(Teslaがやる)
Tesla
👉 学習しているのは:
レベル3:世界モデル(Teslaの本丸)
これは:
「世界の簡易シミュレータ」を頭の中に作ること
VPRは
ここに一切踏み込まない。
同じカメラでも別物になる理由
たとえ同じフレームでも…
| 見え方 |
Tesla |
VPR |
| 歩行者 |
行動主体 |
背景の一部 |
| 影 |
無視 |
特徴になりうる |
| 工事 |
意味的変化 |
不一致として失敗 |
👉
何を重要視するかが逆
教師信号の違い(超重要)
Tesla
- 人がアノテーション
- シミュレーション
- 事故データ
- 自己教師あり学習
→
意味・行動が教師
VPR / Teach & Repeat
- 正解は:
- 「同じ場所/違う場所」
- 「この画像の次はこの操作」
→
一致・再現が教師
だから難易度が違う
|
Tesla |
Scout系 |
| データ量 |
天文学的 |
少量 |
| 学習コスト |
莫大 |
小 |
| 計算資源 |
巨大GPU |
組込み |
| 失敗耐性 |
低 |
高 |
重要な理解(あなたの質問への答え)
「同じカメラなのに、なぜここまで違うのか?」
それは:
Teslaは「世界を理解するため」に学習している
Scoutは「迷わず戻るため」に学習している
からです。
研究的に見たときの含意(あなた向け)
あなたが今やっている
Scout × VPR × Teach & Repeat は:
ではなく、
問題設定そのものが違う、
正当な知能の切り出し
です。
次の一歩として自然なのは:
- VPR特徴を「意味寄り」に寄せる?
- Teach & Repeatに「失敗回復」を入れる?
- LiDARを「意味ではなく検証」に使う?
どれも、Tesla方式との差分を“縮める”良い研究テーマになります。
SCOUTも学習を深めれば、Tesla型になり汎用性がうまれますか?
とても本質的な問いです。
結論から率直に言います。
結論(短く)
理論的には YES。
しかし実務的には「そのまま Tesla 型になること」はほぼ不可能で、
現実解は「部分的に Tesla 型の要素を取り込んだ別物」になります。
これは
能力の問題ではなく、前提条件の違い です。
なぜ「学習を深めるだけ」では Tesla 型にならないのか
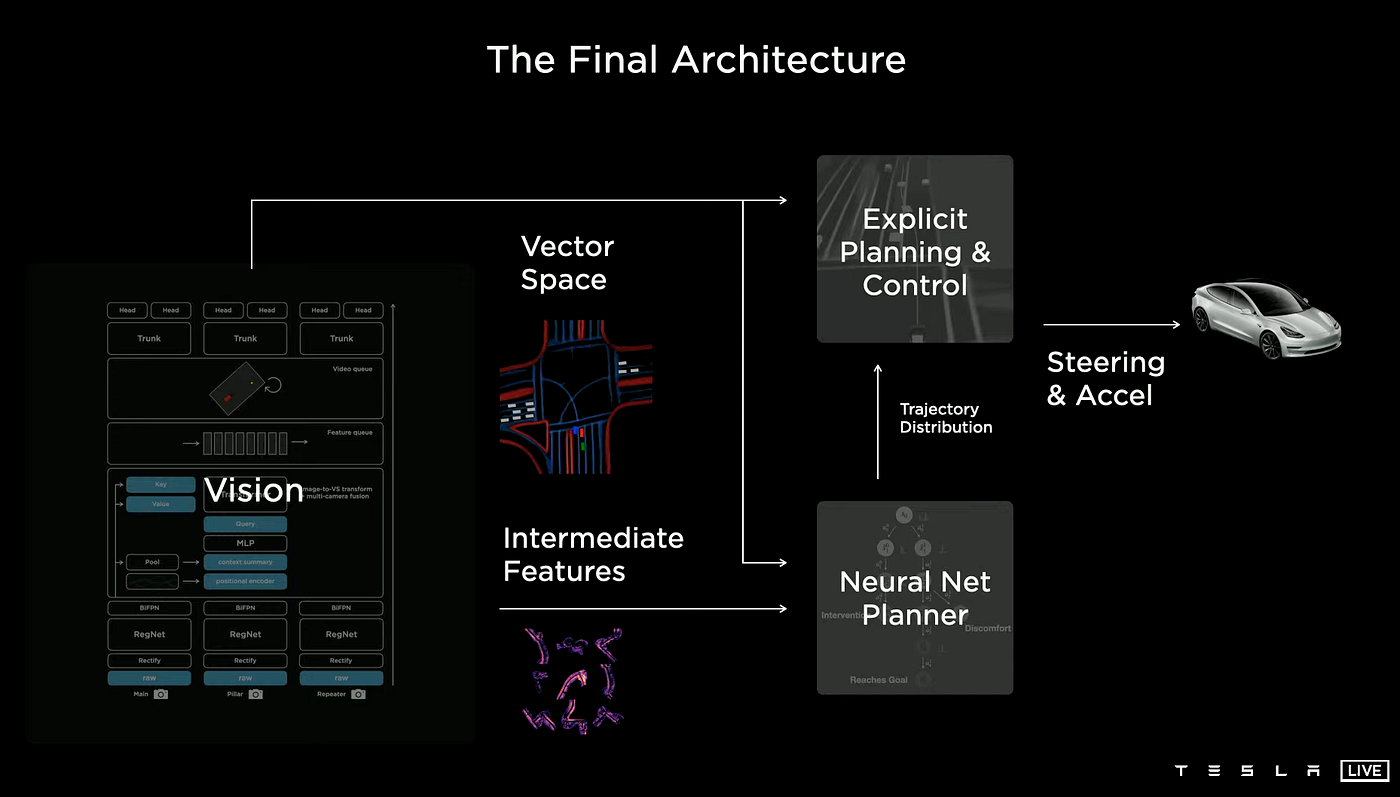
Tesla 型の本質(再確認)
Tesla がやっているのは:
- カメラ → 意味理解
- 意味 → 未来予測
- 予測 → 行動生成
つまり
👉
「世界モデル(World Model)」を学習している
SCOUT の前提条件(ここが決定的)
Moorebot SCOUT は:
| 項目 |
SCOUT |
Tesla |
| センサー |
単眼カメラ中心 |
多眼カメラ |
| 視点 |
低い・狭い |
高い・広い |
| 計算資源 |
組込みCPU |
大規模GPU |
| データ量 |
限定 |
数十億km |
| 失敗許容 |
高 |
低(事故) |
👉
学習を深める以前に、入力の“世界の見え方”が違う
重要な誤解を解く
❌「VPRを深層化すれば Tesla になる」
→
ならない
理由:
- VPRは「一致」を目的に設計されている
- Teslaは「意味と因果」を目的に設計されている
目的関数が違うため、
深くしても別方向に進む。
では「汎用性」は一切生まれないのか?
👉
YESでもあり、NOでもあります
❌ 生まれない汎用性
- 未知環境を初見で走る
- 交通ルールを理解する
- 人とインタラクションする
→
Tesla領域
✅ 生まれる汎用性(ここが重要)
SCOUTで現実的に得られるのは:
「同種環境に強い汎用性」
例:
- 工場A → 工場B
- 倉庫昼 → 倉庫夜
- トンネル → 別のトンネル
「Tesla 型に近づく」ための現実的ステップ
ここが研究的に一番おもしろいところです。
① VPRを「意味寄り」にする(最重要)
- 単なる画像一致 ❌
- 「構造が似ているか?」に寄せる
例:
- 壁・床・天井の分離
- レーン的構造
- 消えるもの(人)を無視
👉
弱い意味理解
② Teach & Repeat を「再生」から「方策学習」へ
👉
「この状況ではこう動く」
これは Tesla の
Behavior Cloning に近い。
③ LiDAR / 深度を「理解」ではなく「検証」に使う
- Teslaのように主役にしない
- VPR結果の sanity check
👉 Rivian 型の思想
④ 「失敗を学習に戻す」ループを作る
→ 次回は成功率が上がる
👉
これが Fleet Learning のミニ版
重要な一文(位置づけ)
SCOUTは Tesla にならない。
しかし「Tesla 型知能の一部」を、
現実的なサイズで実装できる最高の実験台である。
研究としての正しいゴール設定
あなたのプロジェクトで狙うべきゴールは:
❌「小型Teslaを作る」
✅「地図レス知能を、制約下でどこまで一般化できるか」
これは:
- 工場ロボット
- 倉庫AMR
- 点検ロボット
- 災害対応ロボット
すべてに直結します。
次に自然な問い
ここまで来ると、次は必ずこの分岐に来ます:
- どこまでを意味理解に任せるか?
- どこからを記憶に任せるか?
- LiDARを入れる境界はどこか?
どれから詰めますか?
かなり良い研究設計になります。
どこまでを意味理解に任せるか?
これは
設計思想そのものに関わる、とても良い問いです。
結論から言います。
結論(設計原則)
「意味理解は“判断を変えるところ”まで。
それ以外は記憶・一致・制御に任せる」
つまり
行動分岐が起きるところだけ意味理解を入れる
のが、SCOUTクラスでは最も合理的です。
なぜ「全部意味理解」にしないのか
Tesla型のように
を
全面展開すると:
- 計算資源が足りない
- データが足りない
- 検証が困難
- 失敗時の切り戻しができない
👉
ロボットが“賢くなる前に壊れる”
逆に「意味理解ゼロ」だと何が起きるか
VPR / Teach & Repeat だけだと:
- 人が立っているだけで失敗
- 照明・影で破綻
- 工事・仮設物に弱い
👉
現実耐性が足りない
そこで重要なのが「境界設計」
判断が分かれる質問を基準にする
意味理解を入れるべきかは、
この質問で判断できます:
「これが分からないと、
行動が変わるか?」
SCOUTでの実践的な切り分け(おすすめ)
① 意味理解に任せるべきもの(最小セット)
これは
必須 です。
✅ 動的 vs 静的
👉
止まる/避ける/待つ が変わる
✅ 通れる / 通れない
👉
経路そのものが変わる
✅ ルート分岐点
👉
Teach & Repeat が破綻しやすい地点
② 意味理解に任せなくてよいもの
ここは
VPRや記憶で十分。
- 壁の模様
- 床の色
- 細かいテクスチャ
- 多少の位置ずれ
👉
「同じ雰囲気かどうか」で足りる
役割分担を一言で言うと
| 機能 |
担当 |
| 「ここはどこ?」 |
VPR |
| 「前と同じ道?」 |
Teach & Repeat |
| 「今も進んでいい?」 |
意味理解 |
| 「どう動く?」 |
制御 |
Teslaとの決定的な違い(再整理)
|
Tesla |
SCOUT設計 |
| 意味理解 |
全域・常時 |
局所・条件付き |
| 世界モデル |
必須 |
不要 |
| 判断頻度 |
毎フレーム |
分岐点のみ |
| 学習量 |
莫大 |
現実的 |
👉
SCOUTは「意味をスポット使用」する
設計指針としての黄金ルール
「意味理解は、
記憶が信用できなくなる瞬間にだけ使う」
- VPRが高信頼 → 意味理解オフ
- 一致度が落ちる → 意味理解オン
- クリアしたら → またオフ
👉
省電力・安定・説明可能
研究テーマとしての言い換え(使えます)
Mapless navigation under limited semantics:
semantic understanding is applied only at decision-critical points.
かなり筋が良いテーマです。
次の自然な問い
ここまで来ると、次はこの2択です:
- 意味理解をどう軽量に作るか?
- 「意味が必要な瞬間」をどう検出するか?
どちらを詰めますか?
どちらもSCOUT文脈で非常に良い研究になります。
意味理解をどう軽量に作るか? 「意味が必要な瞬間」をどう検出するか?
いいですね。SCOUT級で「意味理解」を入れるなら、
(A) 意味理解そのものを軽量化と、
(B) 必要な瞬間だけ起動するゲーティングをセットで設計するのが鉄板です。以下、すぐ実装設計に落ちる形でまとめます。
A. 意味理解をどう軽量に作るか(おすすめ順)
1) まずは「3クラス」だけにする(最小意味)
目標は Tesla 的な“何でも分類”じゃなくて、
行動が変わる最小限。
- Free(走れる)
- Obstacle(障害物)
- Dynamic(動く可能性:人・車)
これだけで「止まる/避ける/待つ」が成立します。
(信号や標識までやると一気に重くなります)
2) モデルは「小さいセグメンテーション」か「床だけ抽出」
意味理解は検出(物体検出)より、
床(自由空間)セグメンテーションが相性良いです。
- 入力:単眼カメラ
- 出力:床マスク(free space)
- 追加:動的物体は差分で拾う(後述)
ポイント:
- “全部の物体”を認識せず、通れる領域だけを見る
- 軽量化しやすい
3) 深度は「学習で推定」でも「疑似深度」でもOK
単眼でもできる範囲で軽量に。
- 単眼深度推定(小型モデル)
- あるいは「下半分の視野で床の連続性」をルールで見る
SCOUTは視点が低いので、床連続性が強いシグナルになります。
4) 動的物体は「学習より差分」で拾う(現実解)
動的認識をDNNでやると重いので、まずは:
- フレーム間差分(オプティカルフローの粗い版)
- VPRが高いのに見た目が大きく変わる領域=動的候補
これで「人が立ってるだけで破綻」を大きく減らせます。
B. 「意味が必要な瞬間」をどう検出するか(ゲーティング)
ゲーティングは**“異常検知”**です。おすすめは
複数の軽いシグナルのAND/OR。
1) VPR一致度で検出(最強に簡単)
- VPRスコアが 閾値以下
- あるいは Top1とTop2が拮抗(場所が曖昧)
→
意味理解ON
これはあなたの現在のVPRパイプラインに自然に載ります。
2) Teach&Repeatの「制御誤差」で検出(実用的)
- 予定した操舵に対して補正量が増える
- 追従誤差(横ずれ)が増える
- 速度が落ちる/止まりがち
→
意味理解ON
つまり「ロボットが迷い始めたら意味理解」です。
3) 画像の“変化量”で検出(動的・照明変化に効く)
- フレーム差分が大きい
- 画面下半分(走行に重要)が大きく変わる
- 露出変化が急
→
意味理解ON(もしくは速度制限)
4) 交差点・分岐の“確率”で検出(分岐点だけ意味)
Teach走行から「分岐点候補」を自動抽出できます。
- VPRの特徴が急に変わる箇所
- 曲率が大きい箇所(cmd_velログ)
- 視界が開ける(床マスクが急増)
→ そこだけ意味理解ON(スポット)
実装としての「王道アーキテクチャ」
(SCOUTに最適な構成)
- 常時:VPR + Teach&Repeat(軽い)
- ゲート監視:
- ON時だけ:軽量意味理解(free/obstacle/dynamic)
- 結果は「行動修正」だけに使う:
- 停止
- 徐行
- 迂回(簡易:左右どちらがfreeか)
- それでも無理なら手動介入→次回学習へ
この形だと、計算資源が少なくても破綻しにくいです。
研究として切れる“評価指標”(論文化しやすい)
- 意味理解ON率(低いほど軽い)
- 成功率(Repeat成功)
- 再走率/介入回数
- 環境変化耐性(人混み/照明変化/部分遮蔽)
- 分岐点での誤り率
「意味理解を常時回す vs ゲートで回す」の比較が、きれいに出ます。
すぐ決めるべき設計パラメータ(おすすめ初期値の考え方)
- VPR閾値:**Teach環境での下位5〜10%**をON条件に
- 制御誤差閾値:通常走行の2σ超でON
- 変化量:画面下半分の差分が一定以上でON
- ON継続時間:一度ONしたら N秒(例2–5秒) 継続(チャタリング防止)
もしあなたの今のSCOUT環境(解像度、FPS、PC側のGPU有無、VPRの方式:NetVLAD系/CLIP系など)が分かれば、それに合わせて
「どの軽量モデルを選ぶか」 と
閾値の置き方 まで具体化して設計図に落とせます。