
目次
AutoResearchとは
Andrej Karpathy氏が提唱したAutoResearchは、AIエージェントが論文検索・要約・整理を自動化する「AI自動研究」の概念とツール群だ。研究者の情報収集コストを劇的に下げることを目指している。
基本的な仕組み
- 研究テーマや論文IDをエージェントに入力
- ArXivやSemanticScholarからPDFを自動取得
- LLMが論文を要約・関連付け・構造化
- ローカルのMarkdownまたはNotion等に自動保存
- 「この論文と関連する研究を5件探して」等の追加指示が可能
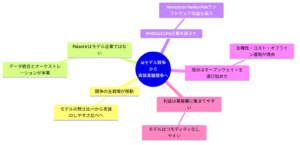
現時点での可能性と限界
可能:サーベイ論文の補完・キーワード周辺の網羅的収集・要約の高速生成
困難:新規性の判断・実験手法の批判的評価・査読品質の維持
活用シーン
- 新分野のキャッチアップ:100本の論文を一週間で把握
- 特許調査の補助:先行技術の概要を素早く収集
- 企業R&D:競合技術動向の定期モニタリング
まとめ
AutoResearchはAIが「研究をする」のではなく「研究者を支援する」ツールだ。情報収集の時間を削減し、研究者が本質的な思考に集中できる環境を作る。
AI・テクノロジーを深く学ぶおすすめ書籍




コメント