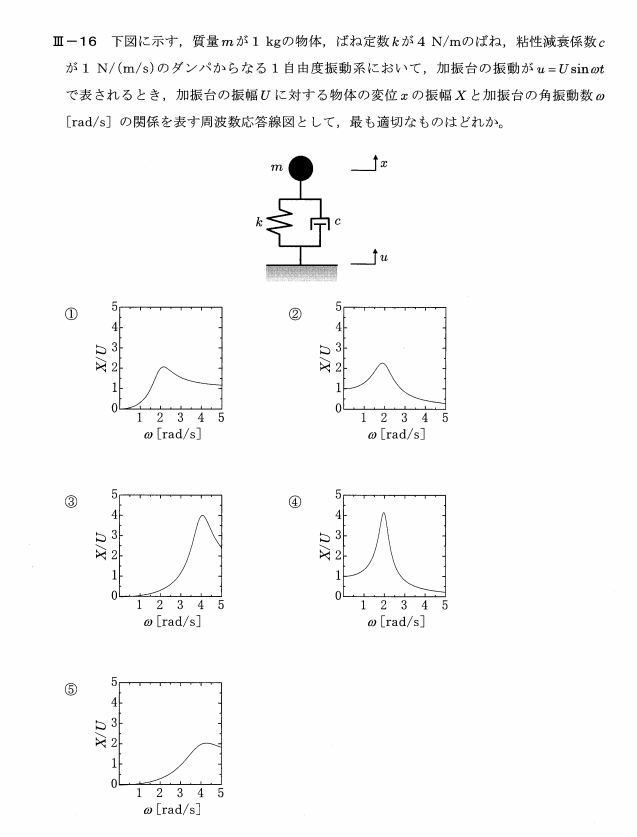
定理
平均μ、分散σ2の正規分布に従う独立な確率変数X1、X2、・・・Xnがあるとする、このとき
$T=\frac{X-μ}{\frac{U}{\sqrt{n}}}$は自由度n-1のt分布に従う
t分布の特徴
・左右対称
・正規分布をつぶした形
・nが大きくなると正規分布に従う
母集団
μ=?
σ2=?
標本(94,99、86、101)
n=4
X=95
$u^2=\frac{(94-95)^2・・・+(101-95)^2}{4-1}=44.67$・・・不変分散
u=6.68
$95-3.18\frac{ 6.68 }{ \sqrt{2}}<μ<95+3.18\frac{ 6.68 }{ \sqrt{2}}$
$84.4≦μ≦105.6$
●5回目 区間推定:母集団分布が未知な場合
・標本をたくさん集める
・不変分散で代用する
中心極限定理
平均μ、分散σ2の母集団から抽出した標本の大きさnが十分大きいとき、標本平均Xは近似的に平均μ、分散$\frac{σ^2}{n}$の正規分布に従う
$X-1.96\frac{ σ }{ \sqrt{n}}<μ<X+1.96\frac{ σ }{ \sqrt{n}}$
ここでnが十分大きいので、σをU(不変分散からもとまる標準偏差)でそのまま置き換えて
$X-1.96\frac{ U }{ \sqrt{n}}≦μ≦X+1.96\frac{ U }{ \sqrt{n}}$を信頼区間95%の信頼区間とする
●6回目 母比率の推定
母比率:p
標本比率:R
母比率の95%信頼区間を求める
角Xiはベルヌーイ分布に従う(平均:p、分散:p(1-p))
→nが十分大きいとき、中心極限定理より
X=(X1+X2+・・・・+Xn)/n=R
は平均p、分散p(1-p)/nの正規分布に従う
$R-1.96\sqrt{\frac{ p(1-p)}{n }}<p<R+1.96\sqrt{\frac{ p(1-p)}{n }}$
ここで、nが十分大きいから
$\sqrt{\frac{ p(1-p)}{n }}$を$\sqrt{\frac{ R(1-R)}{n }}$に置き換えて、
$R-1.96\sqrt{\frac{ R(1-R)}{n }}<p<R+1.96\sqrt{\frac{ R(1-R)}{n }}$
ex.ヨビノリの認知率を調べるために、無作為に選んだ理系大学生400人に「このチャンネルを知っているか」と聞いたところ、320人が「知っている」と答えた。全国の理系大学生への認知率pを信頼度95%で推定せよ。
$0.8-1.96\sqrt{\frac{ 0.8(0.2)}{400 }}≦p≦0.8+1.96\sqrt{\frac{ 0.8(0.2)}{400 }}$
$0.7608≦p≦0.8392$
●7回目 母分散の推定
母集合:μ=?、σ2=?、正規分布
標本集合:
定理
分散σ2の正規分布に従う独立な確率変数X1,X2、・・・Xnがあるとする。このとき
$T=\frac{(n-1)U^2}{σ^2}$
は自由度n-1のχ2分布に従う
●特徴
・左右非対称
・自由度によって形状が大きく変わる
------ex.おかし------
母集合
μ=?
σ2=?
標本集合
n=10
X=9.90
U2=0.25
自由度9のχ2分布
下側2.5%点:2.7
上側2.5%点19.0
$\frac{ (n-1)U^2}{19.0}<σ^2<\frac{ (n-1)U^2 }{ 2.70}$
$0.118<σ^2<0.833$
------------
●8回目 母平均の検定
------ex.------
あるメーカーが「この製品の内容量は150mLです」と主張している。しかし最近この量が減ったのではないかと疑っている。そこで、この製品100個を無作為に抽出して調べてみたところ、その平均は148.5mlであった。このことから「平均内容量は減った」といえるか。内容量の分布は母分散8.02の正規分布とし、優位水準5%で検定せよ。
平均:150
分散:8.02/100(8/10)
棄却域(5%点):148.7
●検定の流れ
- 帰無仮説H0と対立仮説H1を設定。
- H0のもとで対象となる統計量の分布を調べる
- 有意水準(危険率)を決め、2の分布においてH1に有利となる棄却域を設定
- 標本を抽出し、統計量が棄却域にあるかを調べ、棄却域にあればH0を棄却する
定理
同じ母平均と母分散をもつ2つの正規母集団A,Bから、それぞれ大きさna,nbの標本を抽出したとする、このとき
$T=\frac{ (Xa-Xb)}{\sqrt{(\frac{ 1}{ Xa}+\frac{ 1}{ Xb}){\frac{ (na-1)Ua^2+(nb-1)Ub^2}{na+nb-2 }}}}$を
は自由度na+nb-2のt分布に従う。