
①:Data Movement Bottlenecks to Large-Scale Model Training: Scaling Past 1e28 FLOP
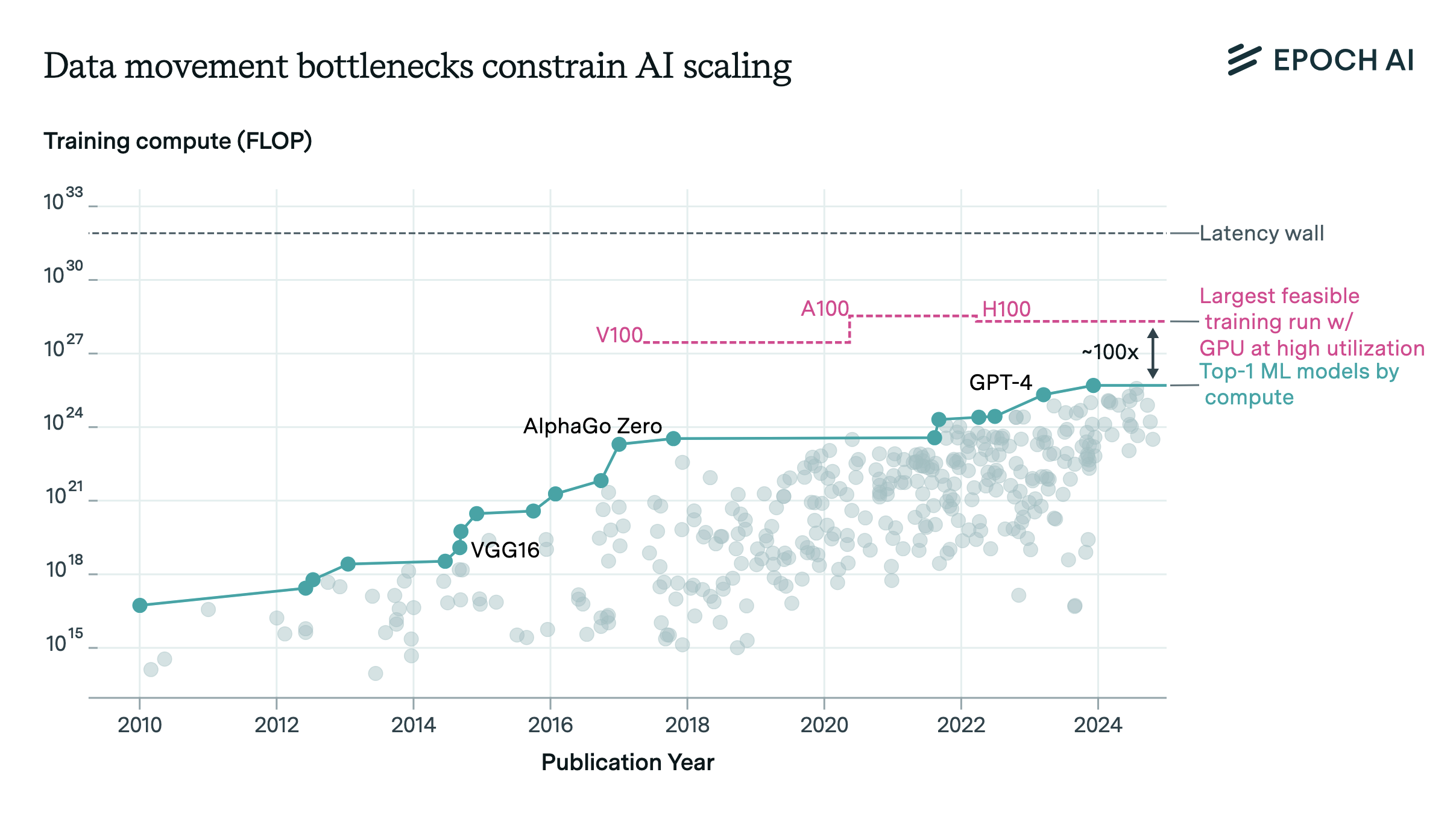
大規模言語モデル(LLM)の性能向上は、トレーニング計算量の急速な増加によって支えられてきました。しかし、計算資源の増加に伴い、データ移動のボトルネックが顕在化し、特に2e28 FLOP(浮動小数点演算)を超える規模では効率的なトレーニングが困難になると指摘されています。
データ移動のボトルネックは、主に以下の2つの要因から生じます:
GPU内部のデータ移動(Intra-GPU):各GPU内でのデータの読み書きや計算処理に伴う遅延。
GPU間のデータ移動(Inter-GPU):複数のGPU間でのデータ通信に要する時間。
これらの遅延は、モデルの規模が大きくなるほど顕著になり、特に2e31 FLOPを超えると「レイテンシの壁」と呼ばれる限界に達する可能性があります。
この問題を克服するためのアプローチとして、バッチサイズの積極的な拡大やモデルの深さの削減が提案されています。しかし、これらの手法には限界があり、データ移動の効率化や新たなハードウェアアーキテクチャの導入が求められています。
総じて、LLMのさらなるスケーリングには、データ移動の最適化が不可欠であり、今後の研究と技術革新が鍵となるでしょう。
レイテンシの壁について解説して下さい
レイテンシの壁とは、コンピュータシステムやネットワークにおいて、**遅延(レイテンシ)**がシステムの性能向上を制限する要因となる状況を指します。特に、計算性能が飛躍的に向上しても、データの移動や通信の遅延がその速度向上に追いつかない場合に問題となります。
背景と原因
データ移動の限界
高性能な計算機(例: GPUやスパコン)では、演算自体は非常に高速ですが、データをメモリから計算ユニットへ移動させる速度(バンド幅)や、複数の計算ユニット間でデータをやり取りする速度がボトルネックとなります。この遅延が累積すると、全体の処理速度が著しく低下します。
計算速度と通信速度の不均衡
ハードウェアの設計上、演算性能(FLOPS: 浮動小数点演算数)は比較的簡単に向上できても、通信やデータ移動の性能(レイテンシやバンド幅)は物理的・設計的な制約が多く、改善が遅れがちです。
スケーリングの課題
ディープラーニングモデルや大規模シミュレーションのように、計算量が指数的に増えるケースでは、モデルの規模が大きくなるほど、データ移動のコスト(時間やエネルギー)が無視できないほど増大します。これが「レイテンシの壁」を形成します。
レイテンシの壁の影響
GPU内部での影響
各GPU内で、計算ユニットとメモリ間のデータ転送が遅れることで、計算ユニットが待機状態に陥り、全体の処理効率が低下します。
GPU間通信での影響
モデルが複数のGPUに分散している場合、各GPU間でのデータ交換が頻繁に発生します。この通信遅延が大規模化の主な障壁となります。
大規模システムのスケーリング限界
データ移動の遅延が一定を超えると、ハードウェアやアルゴリズムをいくら改良しても、全体の性能は向上しなくなります。
レイテンシの壁を克服する方法
計算と通信の効率化
データ移動を減らすアルゴリズムの工夫(例: モデルの分割や分散学習の最適化)。
計算と通信を同時に進める手法(オーバーラップ通信)。
ハードウェアの改善
メモリと計算ユニットを物理的に近づけた設計(例: チップ内メモリの拡充)。
高速通信を可能にする新たなインターコネクト技術。
モデル設計の工夫
モデルサイズを小さくする(例: パラメータ圧縮)。
必要なデータだけを効率的に扱う設計(例: スパースモデリング)。
「レイテンシの壁」は、計算資源の利用効率やスケーラビリティを高める上で重要な課題であり、今後の技術進化において克服すべき主要なテーマです。
この壁を乗り越えるために、どの企業がどの様な取り組みをしていますか?
レイテンシの壁を克服するため、ベンチャー企業は以下のような取り組みを行っています。
1. コンテンツデリバリーネットワーク(CDN)の活用 スタートアップ企業は、ユーザーに近いサーバーからコンテンツを配信するCDNを導入し、データ転送の遅延を削減しています。
STARTUP TALKY
2. ネットワークアーキテクチャの最適化 ネットワーク構成を見直し、データの流れを効率化することで、レイテンシの低減を図っています。
STARTUP TALKY
3. エッジコンピューティングの導入 データ処理をユーザーの近くで行うエッジコンピューティングを採用し、中央サーバーへの依存を減らすことで、遅延を最小限に抑えています。
IEEE XPLORE
これらの取り組みにより、ベンチャー企業はレイテンシの壁を乗り越え、ユーザーに快適なサービスを提供しています。
②:Letter to Shareholders
パランティア テクノロジーズ Q3 2024 株主への手紙
パランティア テクノロジーズは、2024年第3四半期において、過去最高の純利益1億4,400万ドルを達成し、調整後フリーキャッシュフローも初めて12か月間で10億ドルを超えました。
同社の収益は、前年同期比30%増の7億2,600万ドルに達し、特に米国市場での成長が顕著で、米国政府部門の収益は40%、米国商業部門は54%増加しました。
この成長は、同社の最新プラットフォーム「AIP」の導入と、米国企業や政府機関が人工知能(AI)技術を積極的に採用していることに起因しています。
一方、ヨーロッパの企業や政府機関はAIの採用に遅れをとっており、同社はこれが将来的なリスクとなる可能性を指摘しています。
パランティアは何の企業ですか?
パランティア・テクノロジーズ(Palantir Technologies)は、アメリカ合衆国のソフトウェア企業で、ビッグデータの分析と統合を専門としています。2003年にピーター・ティール氏らによって設立され、主に政府機関や企業向けにデータ解析プラットフォームを提供しています。
ウィキペディア
同社の主要製品には以下があります:
Palantir Gotham:主に防衛や情報機関向けのデータ解析ツールで、テロ対策や犯罪捜査などに活用されています。
Palantir Foundry:企業向けのデータ統合・分析プラットフォームで、複数のデータソースを統合し、意思決定を支援します。
Palantir Apollo:ソフトウェアの継続的なデリバリーとデプロイメントを支援するプラットフォームです。
パランティアは、米国の政府機関や防衛関連組織との強固な関係を築いており、近年では商業分野への展開も進めています。
2020年にはニューヨーク証券取引所に上場し、AIとビッグデータ分野でのリーダー企業として注目されています。
最新プラットフォームAIPとは何ですか?
パランティア・テクノロジーズの最新プラットフォームである**AIP(Artificial Intelligence Platform)**は、企業や政府機関が大規模言語モデル(LLM)やその他のAI技術を活用し、データ分析や意思決定を支援するための統合プラットフォームです。
主な特徴:
データ統合と分析:多様なデータソースを統合し、AIモデルを用いて高度な分析を実施します。
セキュリティとプライバシー:ユーザーのプライベートネットワーク内でAIを活用し、データの安全性とプライバシーを確保します。
柔軟なAIモデルの適用:特定の業務ニーズに合わせてAIモデルをカスタマイズし、効率的な運用を実現します。
AIPは、既存のデータインフラとシームレスに統合できるため、企業や政府機関が迅速にAI技術を導入し、業務プロセスの最適化や新たな価値創出を支援します。
LLMを活用したデータ分析の方法を教えて下さい
大規模言語モデル(LLM)を活用したデータ分析の方法は、従来のデータ分析と異なり、自然言語処理(NLP)や生成型AIの能力を利用して、より高度で効率的な分析を可能にします。以下に具体的な手順と方法を説明します。
1. データの準備
クリーンデータの収集
データ分析を行う前に、対象となるデータを収集し、ノイズ(欠損値や異常値)を取り除く必要があります。LLMは構造化データ(表形式)や非構造化データ(テキスト、画像など)の両方に対応できます。
データのトークン化
テキストデータの場合、LLMはトークン単位で処理を行うため、データをトークンに変換します。このステップはモデルに組み込まれている場合が多いです。
2. LLMの選択と設定
モデルの選定
目的に応じて適切なモデルを選択します。例:
データ要約やレポート生成: OpenAIのGPT、GoogleのBERT。
時系列データの予測: 専用のLLM(例:TimeGPT)。
分析用パイプラインの自動化: パランティアのAIPや特定の商用モデル。
モデルのトレーニングまたはファインチューニング
大規模言語モデルを特定の用途に適応させるため、必要に応じて追加トレーニングを行います。
3. データ分析プロセス
(1) データの解釈
LLMを使用して、大量のテキストデータ(例:ニュース、レビュー、SNSデータ)からトピックの抽出や感情分析を行います。
例: 「顧客のレビューを分析し、主要な不満点を抽出する。」
(2) 要約と洞察の抽出
LLMは、膨大なデータセットの要約や意味の解釈を自動化できます。
例: 売上レポートの膨大な文章を簡潔に要約し、重要なポイントを特定。
(3) パターン認識と予測
LLMを用いて、データ内のパターンや傾向を検出し、将来の予測を行います。
例: 顧客行動のトレンド分析や市場予測。
(4) データクエリと自動化
自然言語クエリを使い、データベースから必要な情報を抽出。
例: 「過去1年間の売上が最も多かった月は?」と入力するだけで結果を返す。
(5) インタラクティブなデータ分析
LLMを使って、チャット形式でデータ分析を行い、ユーザーが質問を重ねながらデータを深掘り。
例: 「この増加の原因は?」と質問し、さらに掘り下げた結果を得る。
4. 結果の活用
ダッシュボード作成
LLMが生成した要約や洞察をもとに、可視化ツール(例:Tableau、Power BI)でダッシュボードを作成。
レポート生成
LLMを活用して、データ分析結果を人間が読みやすい形式でレポート化します。
意思決定の支援
LLMが提示するシミュレーションや予測結果をもとに、具体的なアクションプランを策定。
メリットと注意点
メリット:
自然言語でのインタラクションが可能。
非構造化データの分析が容易。
高度な予測能力を備え、意思決定をサポート。
注意点:
トレーニングデータに依存するため、バイアスのリスクがある。
高度な計算資源を必要とする場合がある。
LLMを使ったデータ分析は、複雑なデータセットの解析を迅速に行い、洞察を引き出す強力な手段です。目的に応じてモデルを適切に選び、効果的に活用することで、ビジネスや研究に大きな成果をもたらします。








コメント