映像版Life is beautifulの開発を読み解いて、ai-podcasterを使ってみる
映像版Life is beautifulの開発
まずは音声のみのポッドキャストからスタートした、映像版Life is beautifulですが、開発も進み、ほぼ自動で、映像の作成まで出来るようになりました。開発しているものは、全て、githubでai-podcasterとして公開しているので、興味がある方は参照してください。
現時点では、以下のステップで作成しています。
ベースになる記事や論文をClaudeに読ませる。必要に応じて、質問をする。
そこに、サンプルを含めた特定のプロンプトを与えて、台本を作らせる。
{
"speaker": "Teacher",
"text": "実はそこにも工夫があるんだ。「蒸留」という技術を使って、大きなAIの知識を小さなAIに移すことができるようになったんだよ。例えば、7Bモデルという比較的小さなAIでも、AIMEで56パーセントの正解率を達成できたんだ。",
}
台本を読み、不足している情報があれば追加するようにClaudeに指示を出す。
満足する台本が出来たら、そこで、ClaudeにText2Image向けのプロンプトを与えて、各セリフに適したプロンプトを生成させる。
{
"speaker": "Teacher",
"text": "実はそこにも工夫があるんだ。「蒸留」という技術を使って、大きなAIの知識を小さなAIに移すことができるようになったんだよ。例えば、7Bモデルという比較的小さなAIでも、AIMEで56パーセントの正解率を達成できたんだ。",
"imagePrompt": "Knowledge distillation process visualization, showing large AI model condensing into smaller efficient model, with performance metrics, tech transfer illustration"
}
src/main.tsを走らせて、各セリフの音声ファイル、および、podcast向けのBGM付き音声ファイルを作る。
src/images.tsを走らせて、各セリフ向けの画像を生成する。
src/movie.tsを走らせて、映像ファイルを作る。
映像を見て、読み間違いなどがあった場合には、台本を変更した上で、5に戻る。
ChatGPTではなくClaudeを使っているのは、(作成している台本を保持する)Artifactの扱いが、Claudeの方が上手だからです。ChatGPTを使うと、指示した以外の余計な変更をしてしまうことがあります。Claudeも完璧ではありませんが、とりあえずは十分です。
当初は、Text2Image向けにセリフを渡したり、セリフから抜き出したキーワードを渡していたりしましたが、Claudeに対して「Text2Image向けのプロンプトを作れ」と言えば作ってくれることを発見して以来、この手法を採用しています。
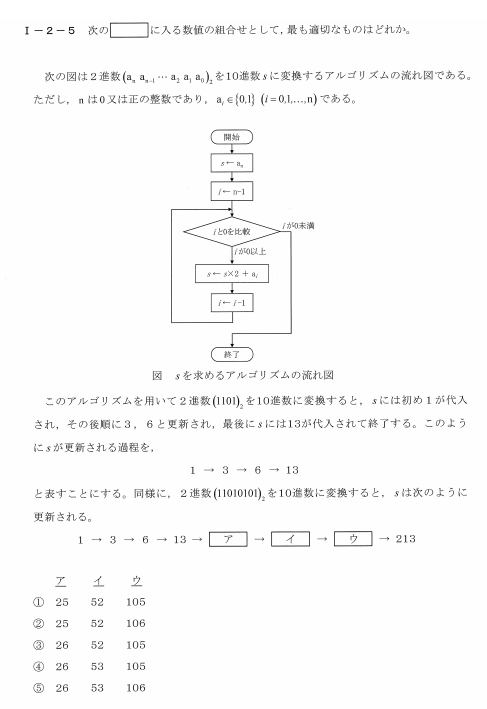
引用:週刊Life is beautiful 2025年2月4日号